___To Be Continued.......
___
___
Camera Settings
___
Position, LookTarget, UpVector...
___
View Matrix
___
URL:
ATTENTION-HERE
URL:
http://www.learnopengl.com/#!Getting-started/Camera
When we're talking about camera/view space we're talking about all the vertex coordinates as seen from the camera's perpective as the origin of the scene: the view matrix transforms all the world coordinates into view coordinates that are relative to the camera's position and direction. To define a camera we need its position in world space, the direction it's looking at, a vector pointing to the right and a vector pointing upwards from the camera. A careful reader might notice that we're actually going to create a coordinate system with 3 perpendicular unit axes with the camera's position as the origin.
...: glm::vec3 CameraPosition;//in World-Space
...: glm::vec3 CameraLookAt;//in World-Space
...: glm::vec3 CameraRight;//in World-Space
...: glm::vec3 CameraUP;//in World-Space
..........................................
A great thing about matrices is that if you define a coordinate space using 3 perpendicular (or non-linear) axes you can create a matrix with those 3 axes plus a translation vector and you can transform any vector to that coordinate space by multiplying it with this matrix.
...
The LookAt matrix then does exactly what it says: it creates a view matrix that looks at a given target.
Luckily for us, GLM already does all this work for us. We only have to specify a camera position, a target position and a vector that represents the up vector in world space (the up vector we used for calculating the right vector). GLM then creates the LookAt matrix that we can use as our view matrix:
....: ViewMatrix BY glm::LookAt()
...............................................................
___
___
Keyboard Input
___
After fiddling around with this basic camera system you probably noticed that you can't move in two directions at the same time (diagonal movement) and when you hold down one of the keys, it first bumps a little and after a short break starts moving. This happens because most event-input systems can handle only one keypress at a time and their functions are only called whenever we activate a key. While this works for most GUI systems, it is not very practical for smooth camera movement. We can solve the issue by showing you a little trick.
The trick is to only keep track of what keys are pressed/released in the callback function. In the game loop we then read these values to check what keys are active and react accordingly. So we're basically storing state information about what keys are pressed/released and react upon that state in the game loop.
___
___
Camera Speed
___
URL:
http://www.glprogramming.com/red/chapter03.html (Official Document)
URL:
http://learnopengl.com/#!Getting-started/Camera (Tutorial with source VSC++)
Currently we used a constant value for movement speed when walking around. In theory this seems fine, but in practice people have different processing powers and the result of that is that some people are able to draw much more frames than others each second. Whenever a user draws more frames than another user he also calls do_movement more often. The result is that some people move really fast and some really slow depending on their setup. When shipping your application you want to make sure it runs the same on all kinds of hardware.
Graphics applications and games usually keep track of a deltatime variable that stores the time it takes to render the last frame. We then multiply all velocities with this deltaTime value. The result is that when we have a large deltaTime in a frame, meaning that the last frame took longer than average, the velocitoy for that frame will also be a bit higher to balance it all out. When using this approach it does not matter if you have a very fast or slow pc, the velocity of the camera will be balanced out accordingly so each user will have the same experience.
___
___
Control Based On Keyboard Keys
___
[0] global variable for keeping key status obtained with KeyCallbackFunction
// Bool Array For key status store;
// Key status obtained with key_callback function;
bool keys[1024];
[1] do something with the position offset according to different key status.
if (keys[GLFW_KEY_W])// CamPos Move Forward, while object Backward
if (keys[GLFW_KEY_S])// CamPos Move Backward, while object Forward
if (keys[GLFW_KEY_A])// CamPos Move Leftward, while object Right
if (keys[GLFW_KEY_D])// CamPos Move Rightward, while object Left
....
[2] calculate position offset.
-direction the camera position offset
glm::cross(_camUP, _camFront)
BY the above, a Leftward Vector obtained.
Normalize the Result Vector...
-scalar multiplied
GLfloat cameraSpeed = (kConstant * _DeltaOfPreviousFrameLast);
-offset
CameraPosition +/-=
___
___
Source Demo..
___
___
___
Eular Angles..
___
URL:
http://learnopengl.com/#!Getting-started/Camera (Tutorial with source VSC++)
 |
| www.learnopengl.com |
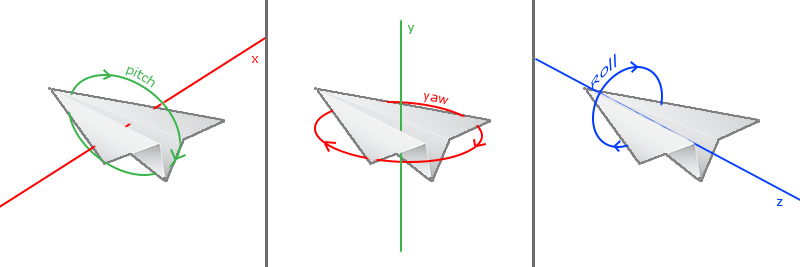
The PITCH is the angle that depicts how much we're looking up or down .
The YAW represents the magnitude we're looking to the left or to the right.
The ROLL represents how much we rolls.
Each of the Euler angles are represented by a single value and with the combination of all 3 of them we can calculate any rotation vector in 3D.
For our camera system we only care about the yaw and pitch values so we won't discuss the roll value here. Given a pitch and a yaw value we can convert them into a 3D vector that represents a new direction vector.
:../Mouse Input
The yaw and pitch values are obtained from mouse (or controller/joystick) movement where horizontal mouse-movement affects the yaw and vertical mouse-movement affects the pitch. The idea is to store the last frame's mouse positions and in the current frame we calculate how much the mouse values changed in comparison with last frame's value. The higher the horizontal/vertical difference, the more we update the pitch or yaw value and thus the more the camera should move.
When handling mouse input for an FPS style camera there are several steps we have to take before eventually retrieving the direction vector:
- Calculate the mouse's offset since the last frame.
- Add the offset values to the camera's yaw and pitch values.
- Add some constraints to the maximum/minimum yaw/pitch values
- Calculate the direction vector(The fourth and last step is to calculate the actual direction vector from the resulting yaw and pitch value)
:../
URL:
https://en.wikipedia.org/wiki/Flight_dynamics
URL:
http://tuttlem.github.io/2013/12/30/a-camera-implementation-in-c.html
The pitch describes the orientation around the X-axis,
such as moving the head Up and Down... (rotate around X)
The yaw describes the orientation around the Y-axis
such as moving the head Left <-> Right... (rotate around Y)
The roll describes the orientation around the Z-axis.
such as moving the head Front <-> Back... (rotate around Z)
With all of this information on board, the requirements of our camera should become a little clearer.We need to keep track of the following about the camera:
Position
Up orientation (yaw axis)
Right direction (pitch axis)
Forward (or view) direction (roll axis)
We’ll also keep track of how far we’ve gone around the yaw, pitch and roll axis.
*****************************************************************************
*
* IMPORTANT CLUE
*
*****************************************************************************
******
******
...
To understand how to make a "camera" in 3D, we must first understand the concept of the clip volume.
The clip volume is a cube. Whatever is inside the clip volume appears on the screen, and anything outside the clip volume is not visible.
The clip volume is a cube. Whatever is inside the clip volume appears on the screen, and anything outside the clip volume is not visible. It has the exact same size as the cube we made above. It ranges from -1 to +1 on the X, Y and Z axes. -X is left, +X is right, -Y is bottom, +Y is top, +Z is away from the camera, and -Z is toward the camera.
Because our cube is the exact same size as the clip volume, all we can see is the front side of the cube.
This also explains why our cube looks wider than it is tall. The window displays whatever is in the clip volume. The left and right edges of the window are -1 and +1 on the X axis, the bottom and top edges of the window are -1 and +1 on the Y axis. The clip volume gets stretched to fit the size of the viewport in the window, so our cube doesn't look square anymore.
...
...
The clip volume can not be changed. It is always the same size, in the same position. So, instead of moving the camera, we must move the entire 3D scene so that it fits inside the clip volume cube correctly.
We want to make a camera that can move around, look in different directions, and maybe zoom in and out.
However, the clip volume can not be changed. It is always the same size, and in the same position.
So, instead of moving the camera, we must move the entire 3D scene so that it fits inside the clip volume cube correctly.
For example, if we want to rotate the camera to the right, we actually rotate the whole world to the left. If we want to move the camera closer to the player, we actually move the player closer to the camera.
This is how "cameras" work in 3D, they transform the entire world so that it fits into the clip volume and looks correct.
When you walk somewhere, it feels like the world is standing still, and you are moving. But you can also imagine that you are not moving at all, and the whole world is rotating underneath your feet, like you are on a treadmill. This is the difference between "moving the camera" and "moving the world." Either way, it looks exactly the same to the viewer.
So how do we transform the 3D scene to fit into the clip volume? This is where we need to use matrices.
...
[]
______________________________________________